
-
锂离子电池以其高能量密度和低使用成本在工程应用中普遍存在,例如新能源汽车、储能电站及便携式电子产品[1-2]。然而,在长期的循环运行下,锂离子电池的性能会出现一定程度的下降,主要表现为容量衰减及功率下降。电池性能下降还可能导致系统故障甚至严重事故,例如火灾和爆炸[3-4]。健康状态(State of Health, SoH)反映了电池当前存储和供应能量/功率的能力相对于其寿命开始时的水平,是锂电池生命周期故障和安全预警的关键参数[5]。准确、有效地估计锂电池健康状态并预测其剩余使用寿命,是提高锂电池甚至锂能平台运行可靠性的有效手段[6]。
电池SoH不能直接通过传感器测量,往往借助于可直接测量的参数(电压、电流、温度)进行间接估计[7]。目前,已有学者提出了许多SoH的估计方法,这些方法可以分为3类,分别为实验法、数值模型与数据驱动方法。实验方法是通过标准充放电直接测量[8]或提取特征指标估计电池容量[9-11]。但实验方法耗时长,不宜用于实际应用中电池SoH实时估计。基于数值模型的方法包括经验模型[12]、电化学模型[13]、等效电路模型[14]等。经验模型通过大量实验数据分析、拟合和统计处理获取SoH的变化规律,但难以适应实际工况变化。电化学模型使用非线性偏微分方程模拟电池内部电化学动力学,可以衡量不同的老化机制,但复杂的建模和计算过程在大规模应用时对计算资源的需求非常高。等效电路模型(Equivalent Circuit Model, ECM)计算量低,实时应用方便且ECM参数能够反映电池容量变化趋势,在SoH评估的应用中具有优势。但ECM模型无法考虑环境温度的影响,导致SoH估计精度较差。数据驱动方法利用电池历史工作数据挖掘容量变化的潜在规律,建模简单且具有优异非线性拟合能力。
近年来,数据驱动方法以其灵活、普适的特点成为SoH估计的研究热点[15]。Li等人[16]应用先进的高斯滤波器方法来获得平滑的增量容量曲线,然后从部分增量容量曲线中提取健康指标来描述其与SoH之间的关系,构建了新型高斯过程回归模型用以SoH估计。Zhou等人[17]从高频和中频范围阻抗谱数据中提取电池健康指标,设计了具有单步延迟反馈回路的递归高斯过程回归模型,以提供平滑且准确的电池健康状态估计。Li等人[18]选取了4个与SoH下降高度相关的健康特征,运用改进的蚁狮算法优化支持向量回归模型的超参数,从而提高了SoH估计的精度和鲁棒性。上述研究中,大多在特征选择方面做了大量的工作,却极少对提取的特征做进一步处理以提高特征与SoH的相关性。特征质量是电池寿命估计模型建模的重要影响因素,噪声大、相关性低的数据会影响数据驱动模型的估计效果。选择合理的特征能够减少模型的开发成本,使模型更加轻量化,提高模型的计算速度。其次,开发合理模型结构,确定有效的模型超参数,同样能够显著提高电池SoH预测结果。
基于上述分析,本文提出基于奇异值分解(Singular Value Decomposition, SVD)定阶降噪和麻雀搜索算法(Sparrow Search Algorithm, SSA)优化门控循环单元(Gate Recurrent Unit, GRU)神经网络的SoH估计方法。首先,从电池充放电数据中选取了3个与SoH衰减相关的指标,分别为恒流充电时间、恒压充电时间和放电平均电压,利用奇异值分解技术对提取的健康指标进行降噪处理,提高其与SoH的相关性,减少噪声对神经网络模型的干扰。然后建立基于门控循环神经网络层的数据驱动模型,并采用麻雀搜索算法对神经网络模型的超参数进行寻优,提高模型对SoH的预测精度。最后,本研究提出的方法在公开数据集中进行验证,并与传统方法进行比较,以表明本方法的优越性。
-
本研究利用先进生命周期工程中心(Centre for Advanced Life Cycle Engineering, CALCE)的电池数据集验证所提方法的有效性[14],选用电池编号为CS2-35,CS2-36和CS2-37的测试数据。所有电池均以0.5 C的恒定电流速率进行充电,直到截止电压4.2 V;接着保持4.2 V充电,直到电流降至0.05 A以下;最后以恒定1 C电流对电池进行放电,直到截至放电电压2.7 V,如表1所示。
参数 规格 标称容量/mAh 1 100 化学成分 LiCoO2 充电截止电压/V 4.2 放电截止电压/V 2.7 Table 1. Battery characteristics
-
SoH是电池管理系统的关键参数,代表电池的退化程度。SoH通常用容量或者内阻来表示,本文采用容量来表示SoH,其定义如下式所示[19]:
$$ {{{\rm{S}}{{\rm{oH}}}}} = \frac{{{Q_{\rm{c}}}}}{{{Q_{\rm{r}}}}} \times 100\text{%} $$ (1) 式中:
$Q_{\rm{c}}$ ——电池当前容量(Ah);
$Q_{\rm{r}}$ ——电池标称容量(Ah)。
-
锂电池运行过程中的电压、电流、温度、时间等数据能够直接测量的,而电池容量通常无法直接测量,只能通过其他手段进行间接估计。电池容量衰减通常用来表征电池的老化过程,因此从可直接测量数据中提取可描述不同尺度电池老化特性的特征对于估计电池健康状态至关重要[20-21]。根据对充放电曲线的观察和分析,本文选取以下3个特征(F1、F2和F3)来估算SoH:
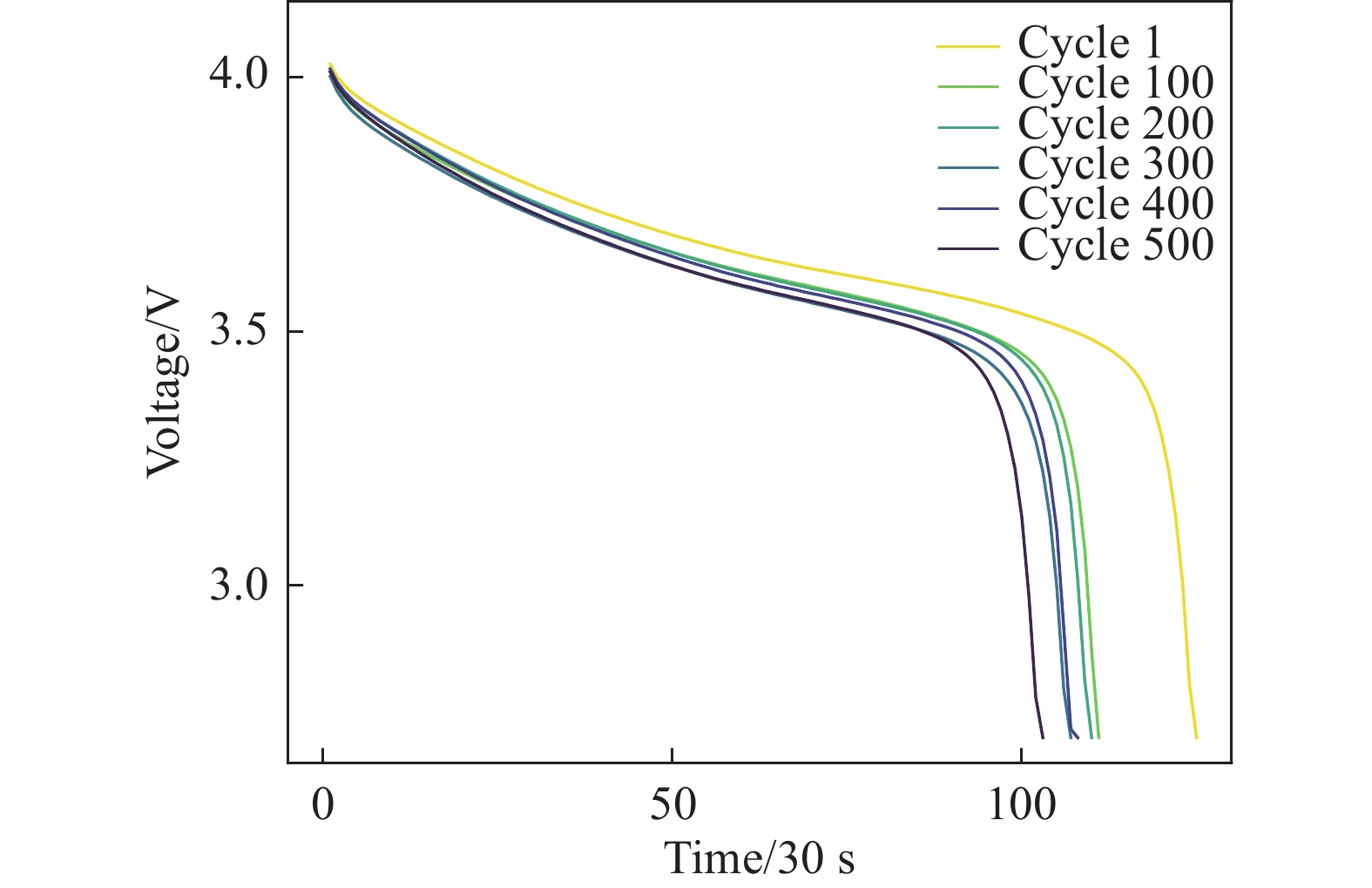
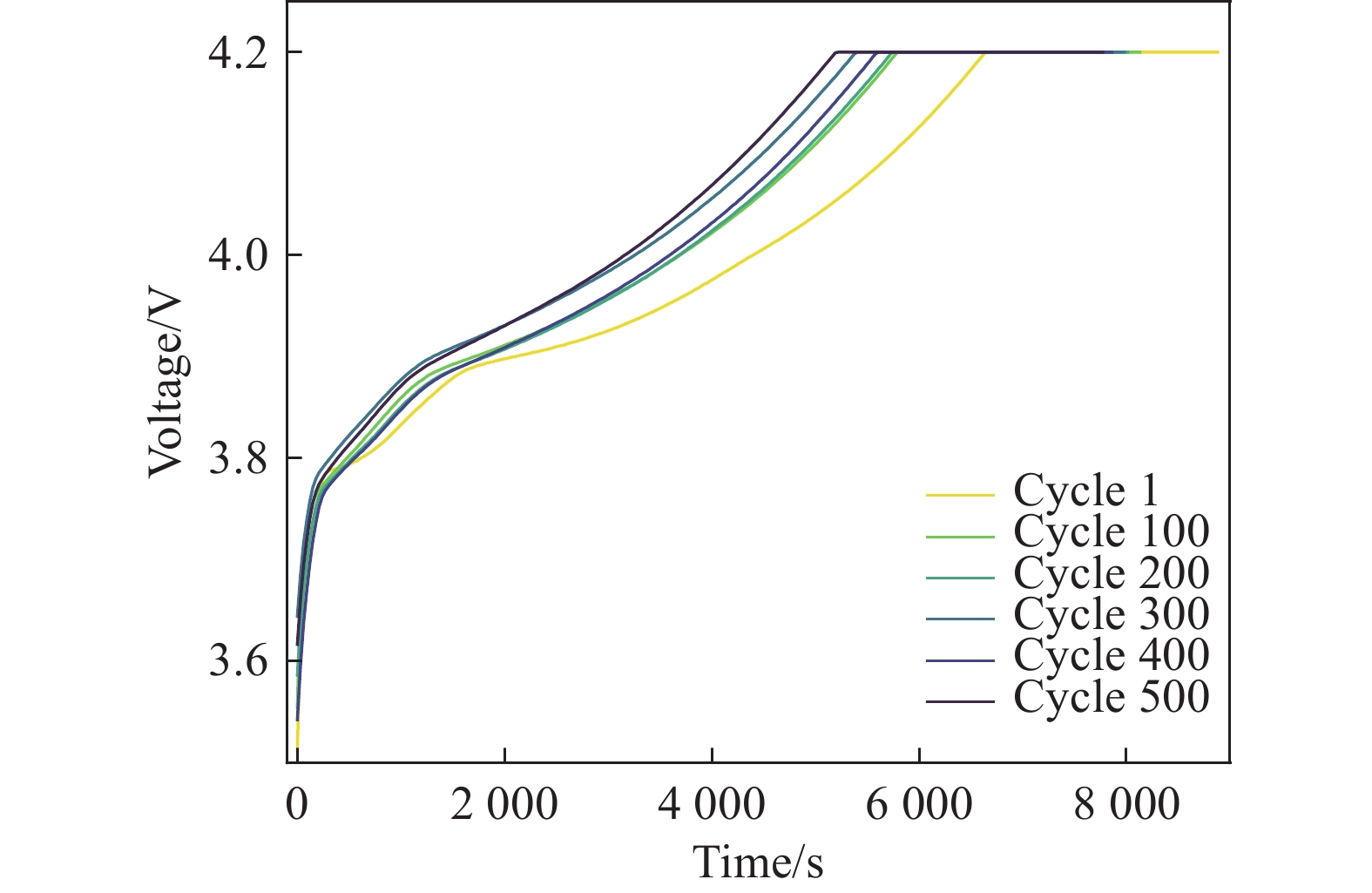
F1:恒流充电时间(Constant Current Charging Time, CCCT),CCCT变化本质上是由于锂电池材料发生了衰变,直接影响电池在恒流阶段可充电容量。随着电池老化,极化程度加剧,电池容量随使用次数不断衰减。如图1所示,电压不断上升的过程为恒流充电阶段,电压恒定的过程为恒压充电阶段。随着循环次数的增加,恒流充电模式的持续时间减少[22]。

Figure 1. CC-CV charging curve
F2:恒压充电时间(Constant Voltage Charging Time, CVCT),恒压充电阶段随着充电电流的减小,电解液中的锂离子逐渐嵌入负极,浓度迅速降低[23]。恒压充电模式用于消除CC模式的极化现象,持续时间越长,电池老化越严重。如图1所示,随着循环次数的增加,恒压充电模型持续的时间增加,CVCT为电池老化的逆向指标。
F3:平均放电电压(Average Discharge Voltage, ADV),如图2所示,随着循环次数的增加,放电电压曲线往左下方移动。平均放电电压随着电池老化逐渐降低,这与SoH的变化趋势一致,可以看作是一种健康特征。
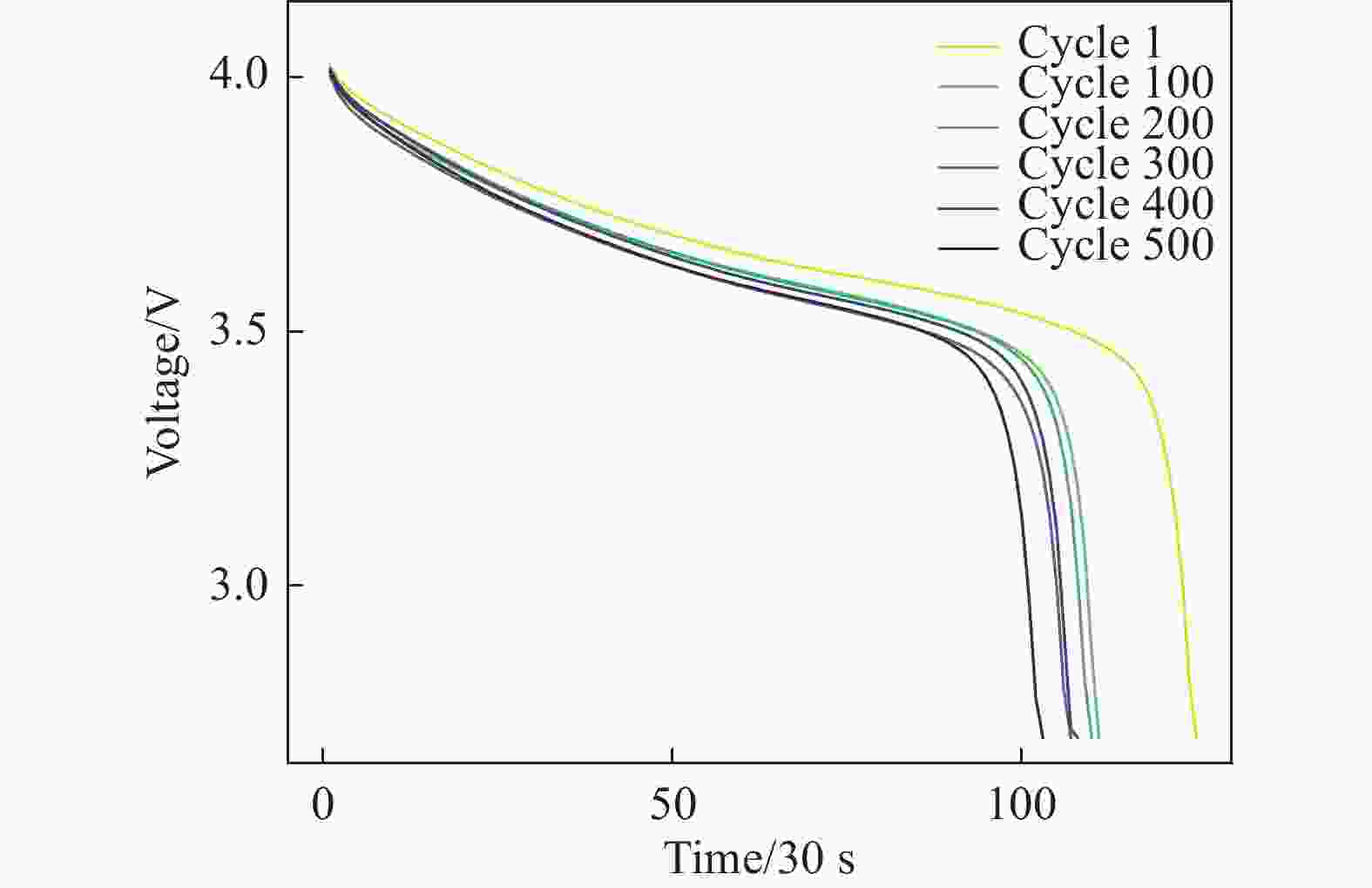
Figure 2. Discharge voltage curve
Spearman秩相关系数可用于定量分析两个变量之间联系的紧密程度。本研究使用Spearman秩相关系数定量分析上述指标与电池SoH之间的相关性。假设$\left( {{x_1}},{{x_2}},\cdots,{{x_n}} \right)$,$\left({{y_1}},{{y_2}},\cdots,{{y_n}} \right)$分别为来自总体$ X、Y $的样本,令$R\left( {{x_j}} \right)$,$R\left( {{y_j}} \right)$分别表示在样本$({{x_1}}, {{x_2}},\cdots,{{x_n}})$,$\left( {{y_1}},{{y_2}},\cdots,{{y_n}} \right)$中的秩,则Spearman秩相关系数计算公式如下[24]:
$$ r\left( {X,Y} \right) = 1 - \dfrac{{6\displaystyle \sum\limits_{j = 1}^n {d_j^2} }}{{n\left( {{n^2} - 1} \right)}} $$ (2) 式中:${d_i} = R\left( {{x_j}} \right) - R\left( {{y_j}} \right)$,$j = 1,2, \ldots ,n$。
Spearman相关系数计算结果如表2所示。相关系数取值为0.8~1,则认为变量之间具有强相关性。CCCT、CVCT与ADV在3个特征的相关性系数均大于0.8,说明本研究提取的特征适用于估计电池SoH。
特征指标 CCCT CVCT ADV Spearman相关系数 CS2-35 0.992 0 −0.939 0 0.942 3 CS2-36 0.993 3 −0.867 5 0.964 1 CS2-37 0.983 6 −0.937 0 0.955 8 Table 2. Calculation results of the Spearman correlation coefficients of feature parameters and SoH
-
1)奇异值定阶降噪
奇异值分解是数学里常用的矩阵分解方法,由于其具有较好的理论基础,近年来在数据降维、噪声控制和信号处理等方面获得了广泛的应用[25]。任意$m \times n$的矩阵A可以分解为如下所示[26]:
$$ {\boldsymbol{A}} = {\boldsymbol{U}}{\boldsymbol{\varSigma}} {{\boldsymbol{V}}^{\boldsymbol{T}}} $$ (3) 式中:
${\boldsymbol{U}}$ ——$\left( {m \times r} \right)$左奇异矩阵;
${\boldsymbol{V}}$ ——$\left( {n \times r} \right)$右奇异矩阵;
$\varSigma$ ——对角矩阵,对角线上是矩阵${\boldsymbol{A}}$的奇异值从大到小排列,$r$为矩阵${\boldsymbol{A}}$的秩数。
$$ {\boldsymbol{\varSigma}} = \left[ {\begin{array}{*{20}{c}} {{\sigma _1}}& \cdots &0 \\ \vdots & \ddots & \vdots \\ 0& \cdots &{{\sigma _r}} \end{array}} \right] = \left[ {\begin{array}{*{20}{c}} {\sqrt {{\lambda _1}} }& \cdots &0 \\ \vdots & \ddots & \vdots \\ 0& \cdots &{\sqrt {{\lambda _r}} } \end{array}} \right] $$ (4) 奇异值可以表示原矩阵在其对应的特征向量上包含的信息,奇异值越大,说明其对应的特征向量在构成原矩阵的过程中承担的作用越大。如果$k\left( {k \leqslant r} \right)$个奇异值数值较大,说明前$k$个奇异值对应的信息是原矩阵的主成分[27],可以将原矩阵重构降噪为$\widetilde A$:
$$ \widetilde {\boldsymbol{A}} = {{\boldsymbol{U}}_{m \times k}}{{\boldsymbol{\varSigma}} _{k \times k}}{\boldsymbol{V}}_{n \times r}^T $$ (5) 经过奇异值定阶降噪后的Spearman相关系数计算结果如表3所示,所有特征相关性系数均大于0.9。并且经过降噪后,所有特征的相关性系数均有一定程度的提升,其中以CVCT提升最为明显。
特征指标 CCCT CVCT ADV Spearman相关系数 CS2-35 0.994 9 −0.953 2 0.966 6 CS2-36 0.993 4 −0.948 0 0.969 0 CS2-37 0.981 1 −0.955 3 0.963 5 Table 3. Spearman correlation coefficients after feature noise reduction
2)归一化
不同变量之间的量级会影响优化算法以及神经网络模型的拟合精度,故将特征按照最大值最小值归一化至[0,1]区间,其公式为:
$$ {y^{'}} = \dfrac{{y - {y_{\min }}}}{{{y_{\max }} - {y_{\min}}}} $$ (6) 式中:
y ——不同的变量;
${y^{'}}$ ——归一化后的值;
${y_{\max }}$ ——变量的最大值;
${y_{\min }}$ ——变量的最小值。
-
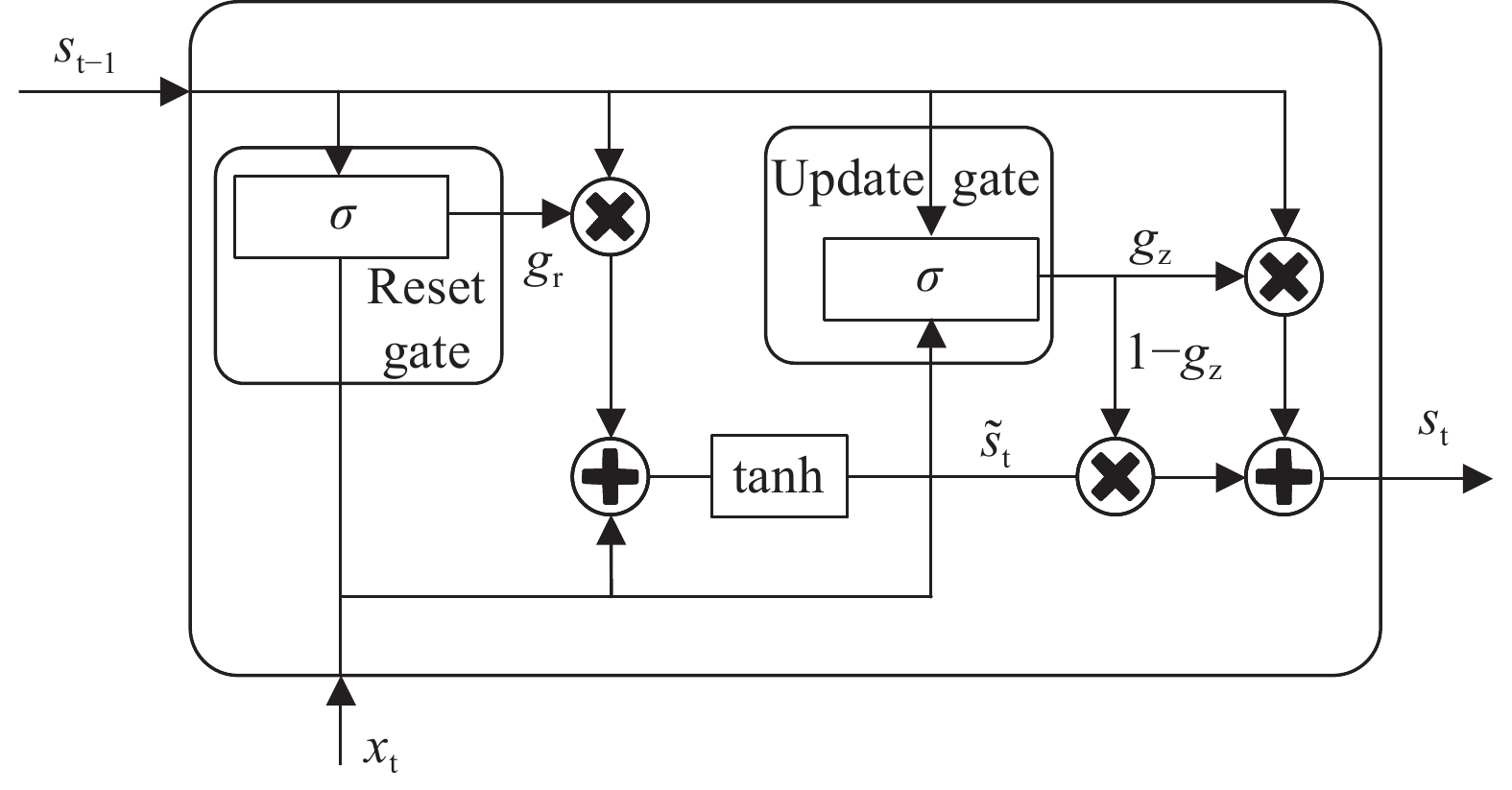
门控循环单元神经网络(GRU)[28]与长短时记忆神经网络相似,GRU由于少了一个门,其结构更加简单。如图3所示,GRU只有两个门:重置门和更新门,这使得模型的参数化程度更低,计算成本更低,训练速度更快。重置门的作用是控制历史信息的保留,重置门的值越大,忽略的历史信息越少。更新门用于控制前一个单元状态和当前新输入对当前新单元状态的影响。GRU的数学计算过程如下:
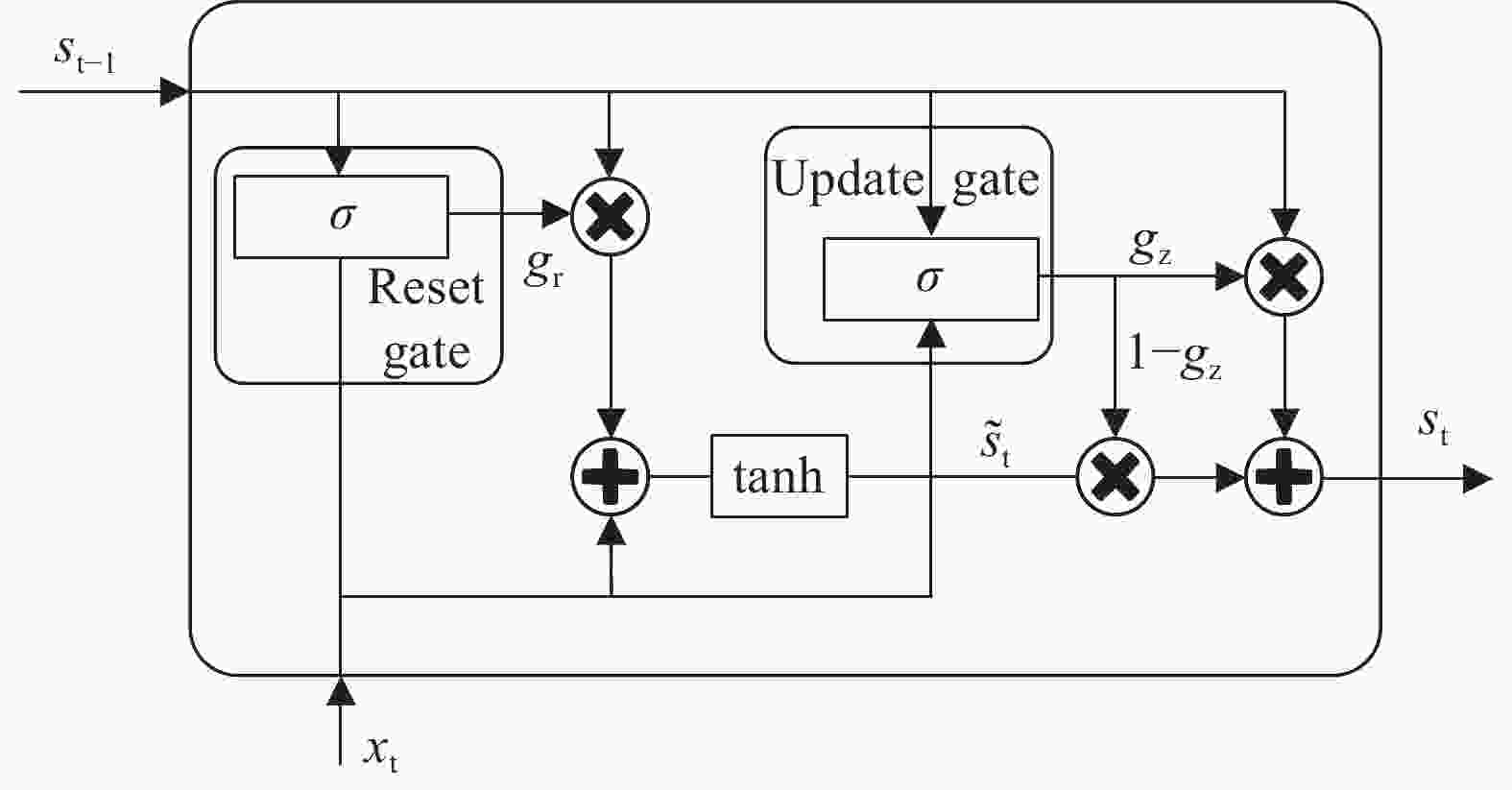
Figure 3. GRU structure diagram
$$ {g}_{{\rm{r}}}=\sigma \left({W}_{{\rm{r}}}\cdot \left[{s}_{{\rm{t}}-1},{x}_{{\rm{t}}}\right]+{b}_{{\rm{r}}}\right) $$ (7) $$ {g}_{{\rm{z}}}=\sigma \left({W}_{{\rm{z}}}\cdot\left[{s}_{{\rm{t}}-1},{x}_{{\rm{t}}}\right]+{b}_{{\rm{z}}}\right) $$ (8) $$ {\widehat{s}}_{{\rm{t}}}=\mathrm{tan}h\left({W}_{{\rm{h}}}\cdot\left[{g}_{{\rm{r}}}\ast {s}_{{\rm{t}}-1},{x}_{{\rm{t}}}\right]+{b}_{{\rm{s}}}\right) $$ (9) $$ {s_{\rm{t}}} = \left( {1 - {g_{\rm{z}}}} \right) * {s_{{\rm{t}} - 1}} + {g_{\rm{z}}} * {\widehat s_{\rm{t}}} $$ (10) 式中:
${g_{\rm{r}}}$——重置门状态;
${g_{\rm{z}}}$——更新门状态;
$\widehat {{s_{\rm{t}}}}$——候选隐藏状态;
${s_{\rm{t}}}$ ——当前隐藏状态;
$W$ ——权重;
$b$ ——偏置;
$ \sigma (·) $ ——sigmoid函数,通过这个函数可以将数据变为0~1范围的数值,如式(11)所示;
$\mathrm{tan}h(·)$ ——tanh函数,通过这个函数可以将数据变为[−1,1]范围的数值,如式(12)所示。
$$ \sigma \left( x \right) = \dfrac{1}{{1 + {{\rm{e}}^{ - x}}}} $$ (11) $$ \tan h \left( x \right) = \dfrac{{{{\rm{e}}^{2x}} - 1}}{{{{\rm{e}}^{2x}} + 1}} $$ (12) GRU架构在处理长时间序列数据方面表现良好,并且可以在不同的时间步共享相同的参数。所选取的特征CCCT、CVCT、ADV均为一维时间序列数据,使用GRU来估计SoH是合理的。所选特征作为GRU神经网络的输入,SoH作为其输出,其映射关系如下式所示:
$$ {{\rm{S}}{{\rm{oH}}}} = f\left( {{F_1},{F_2},{F_3}} \right) $$ (13) -
麻雀搜索算法[29]依据麻雀的觅食行为建立数学模型,通过有规则更新种群位置的方式,找到最优麻雀个体的位置,从而为神经网络模型找到最佳的超参数。
在觅食的过程中,$d$维空间内由$n$个麻雀组成的种群可表示为:
$$ {\boldsymbol{X}} = \left[ {\begin{array}{*{20}{c}} {x_1^1}&{x_1^2}& \cdots &{x_1^d} \\ {x_2^1}&{x_2^2}& \cdots &{x_2^d} \\ \vdots & \vdots & \vdots & \vdots \\ {x_n^1}&{x_n^2}& \cdots &{x_n^d} \end{array}} \right] $$ (14) 式中:
$x_n^d$——第$n$个麻雀个体在第$d$维空间中的参数。
麻雀种群分为发现者和跟随者,具有较高适应度值的麻雀个体选择成为发现者,引导种群进行搜索。加入者根据适应度值的变化决定是否跟随发现者,发现者位置更新规则如下式所示:
$$ X_{i,j}^{t + 1} = \left\{ {\begin{array}{*{20}{l}} {X_{i,j}^t \times \exp \left( { - \dfrac{i}{{\beta \times {t_{\max }}}}} \right)}&{\begin{array}{*{20}{c}} {\begin{array}{*{20}{c}} {}&{} \end{array}if}&{{R_2} > {S_{\rm{T}}}} \end{array}} \\ {X_{i,j}^t + Q \times {\boldsymbol{L}}}&{\begin{array}{*{20}{c}} {\begin{array}{*{20}{c}} {}&{} \end{array}if}&{{R_2} < {S_{\rm{T}}}} \end{array}} \end{array}} \right. $$ (15) 式中:
$t$ ——当前迭代次数;
${t_{\max }}$ ——最大迭代次数;
$ \beta $ ——补偿控制参数,是服从均值为0,方差为1的正态分布的随机数;
${X_{i,j}}$ ——第$i$个麻雀个体在第$j$维中的位置信息;
$Q$ ——服从正态分布的随机数;
${\boldsymbol{L}}$ ——全1矩阵;
$S_{\rm{T}}$ ——安全阈值,${S_{\rm{T}}}\in [0.5,1]$;
${R_2}$ ——麻雀种群位置的预警值,${R_2} \in [0,1]$。
跟随者的位置更新公式为:
$$ X_{i,j}^{t + 1} = \left\{ {\begin{array}{*{20}{l}} {Q \times \exp \left( {\dfrac{{X_{{\rm{worst}}}^t - X_{\rm{p}}^{t + 1}}}{{{i^2}}}} \right)}&{\begin{array}{*{20}{c}} {\begin{array}{*{20}{c}} {}&{} \end{array}if}&{i > \dfrac{n}{2}} \end{array}} \\ {X_{\rm{p}}^{t + 1} + \left| {X_{i,j}^t - X_{\rm{p}}^{t + 1}} \right| \times {{\boldsymbol{A}}^ + } \times {\boldsymbol{L}}}&{\begin{array}{*{20}{c}} {}&{} \end{array}otherwise} \end{array}} \right. $$ (16) 式中:
$X_{{\rm{worst}}}^t$ ——全局最差麻雀位置;
${X_{\rm{p}}}$ ——发现者最优位置;
${\boldsymbol{A}}$ ——矩阵,其每个元素值均在区间[−1, 1]内。
从种群中随机选取15%的麻雀个体成为警戒者,并按照下式更新位置。通过不断更新种群位置,尽可能减小适应度函数值。
$$ X_{i,j}^{t + 1} = \left\{ {\begin{array}{*{20}{l}} {X_{{\rm{best}}}^t + \beta \times \left| {X_{i,j}^t - X_{{\rm{best}}}^t} \right|}&{\begin{array}{*{20}{c}} {\begin{array}{*{20}{c}} {}&{} \end{array}{f_i}}&{ > {f_{\rm{g}}}} \end{array}} \\ {X_{i,j}^t + K \times \left( {\dfrac{{\left| {X_{i,j}^t - X_{{\rm{worst}}}^t} \right|}}{{(\begin{array}{*{20}{c}} {{f_i}}&{ > {f_{\rm{w}}}} \end{array}) + \varepsilon }}} \right)}&{\begin{array}{*{20}{c}} {\begin{array}{*{20}{c}} {}&{} \end{array}{f_i}}&{ = {f_{\rm{g}}}} \end{array}} \end{array}} \right. $$ (17) 式中:
${X_{{\rm{best}}}}$ ——最优麻雀个体的位置;
$\beta $ ——补偿控制参数,是服从均值为0,方差为1的正态分布的随机数;
$K$ ——区间[−1,1]之间的随机数;
${f_i}$ ——当前麻雀个体的适应度值;
${f_{\rm{g}}}$、${f_{\rm{w}}}$ ——当前全局最佳和最差适应度值;
$\varepsilon $ ——常数,避免分母为0。
-
应用麻雀搜索算法对GRU神经网络模型的超参数进行优化。优化的参数包括学习率、迭代次数、神经元数量。麻雀搜索算法的初始参数包括迭代次数、种群数量和优化维度。
麻雀算法优化GRU神经网络步骤如图4所示:
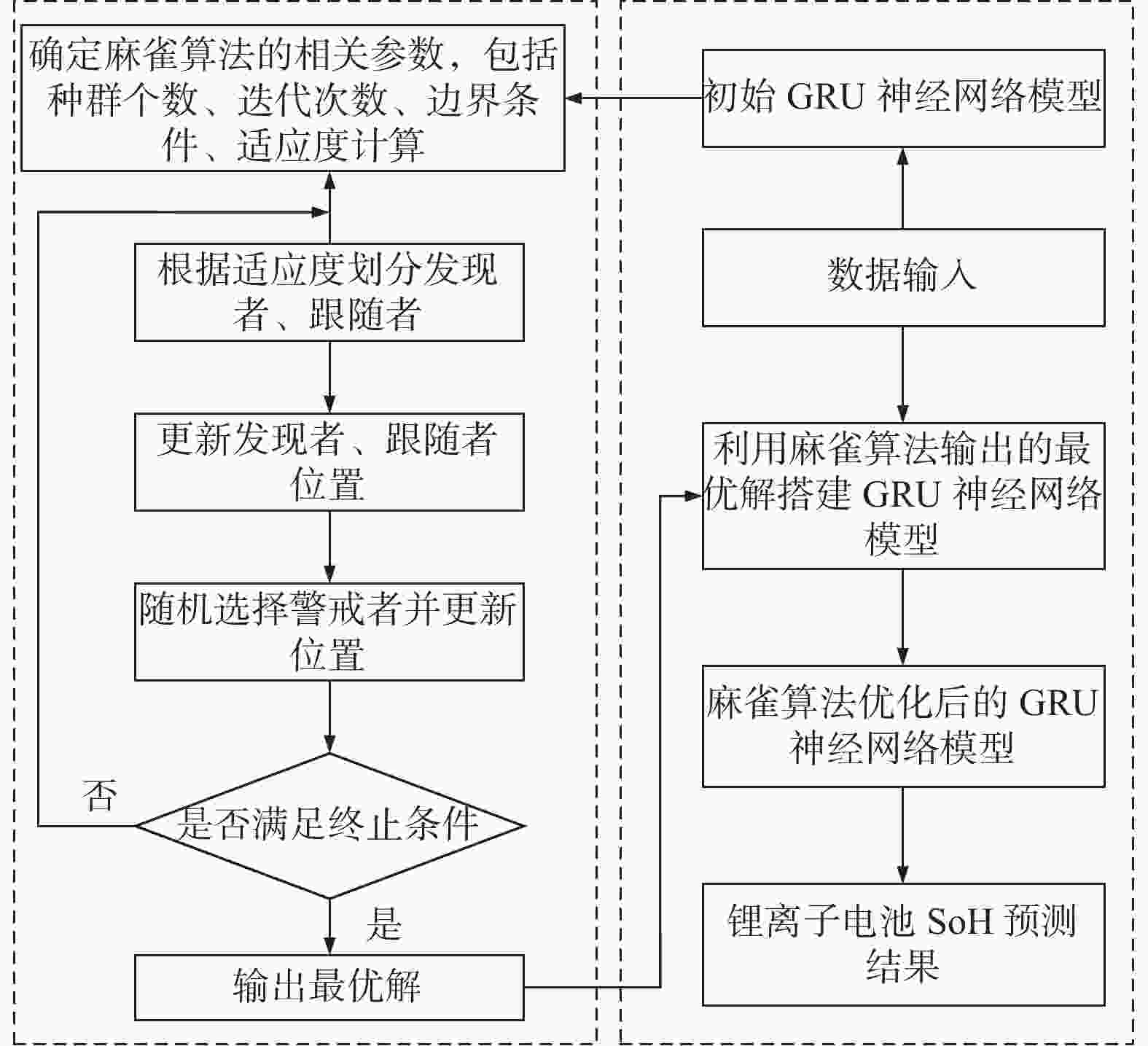
Figure 4. The flow of optimizing the GRU neural network by sparrow search algorithm
Step 1:初始化麻雀搜索算法麻雀种群的数量、麻雀算法迭代次数、算法寻优维度;初始化麻雀种群的位置,其初始种群位置为随机生成。
Step 2:以均方根误差为适应度函数,计算每个麻雀个体的适应度,选择最优麻雀个体,并根据最优麻雀个体更新麻雀种群的位置,种群位置更新公式如式(15)~式(17)所示,适应度函数如下式所示:
$$ {f_{{\rm{it}}}} = \sqrt {\frac{1}{n}{{\sum\limits_{t = 1}^n {\left( {{y_{{\rm{tru}}}}\left( t \right) - {y_{{\rm{pre}}}}\left( t \right)} \right)} }^2}} $$ (18) 式中:
${y_{{\rm{tru}}}}$ ——第$t$个样本的实际值;
${y_{{\rm{pre}}}}$ ——第$t$个样本的预测值;
$n$ ——样本个数。
Step 3:重复执行Step 2,直至满足终止条件,本研究算法终止条件设置为麻雀搜索算法的迭代次数。输出麻雀搜索算法的优化结果,分别为GRU神经网络的学习率、迭代次数、神经元数量。
Step 4:将麻雀搜索算法输出的参数用于GRU神经网络,并用训练样本对网络进行训练,获得锂离子电池SoH预测模型。
-
本研究实验数据来源于先进生命周期工程中心(CALCE)的提供的电池数据集,选用电池编号为CS2-35,CS2-36和CS2-37的测试数据。本实验选取数据的前50%作为训练数据,数据的后50%作为测试集。为了体现本研究所提模型的优越性,将GRU、SVD-GRU和SVD-SSA-GRU 3种模型进行了比较。
-
将均方根误差(Root Mean Square Error, RMSE)、平均绝对误差(Mean Absolute Error, MAE)和平均绝对百分比误差(Mean Absolute Percentage Error, MAPE)作为评价指标来评估模型效果。评价的指标公式如下:
$$ \left\{ \begin{gathered} {{{\rm{RMSE}}}} = \sqrt {\frac{1}{n}{{\sum\limits_{t = 1}^n {\left( {{y_{{\rm{tru}}}}\left( t \right) - {y_{{\rm{pre}}}}\left( t \right)} \right)} }^2}} \\ {{{\rm{MAE}}}} = \frac{1}{n}\sum\limits_{t = 1}^n {\left| {{y_{{\rm{tru}}}}\left( t \right) - {y_{{\rm{pre}}}}\left( t \right)} \right|} \\ {{{\rm{MAPE}}}} = \frac{{100\% }}{n}\sum\limits_{t = 1}^n {\left| {\frac{{{y_{{\rm{tru}}}}\left( t \right) - {y_{{\rm{pre}}}}\left( t \right)}}{{{y_{{\rm{tru}}}}\left( t \right)}}} \right|} \\ \end{gathered} \right. $$ (19) 式中:
${y_{{\rm{tru}}}}$——第$t$个样本的实际值;
${y_{{\rm{pre}}}}$——第$t$个样本的预测值;
$n$ ——样本个数。
-
为说明特征选择的必要性,对GRU神经网络模型输入特征数量为2个和3个的情况进行了讨论。以CS2-35电池为例,在相同模型参数的情况下,不同特征数量的预测结果如图5所示:
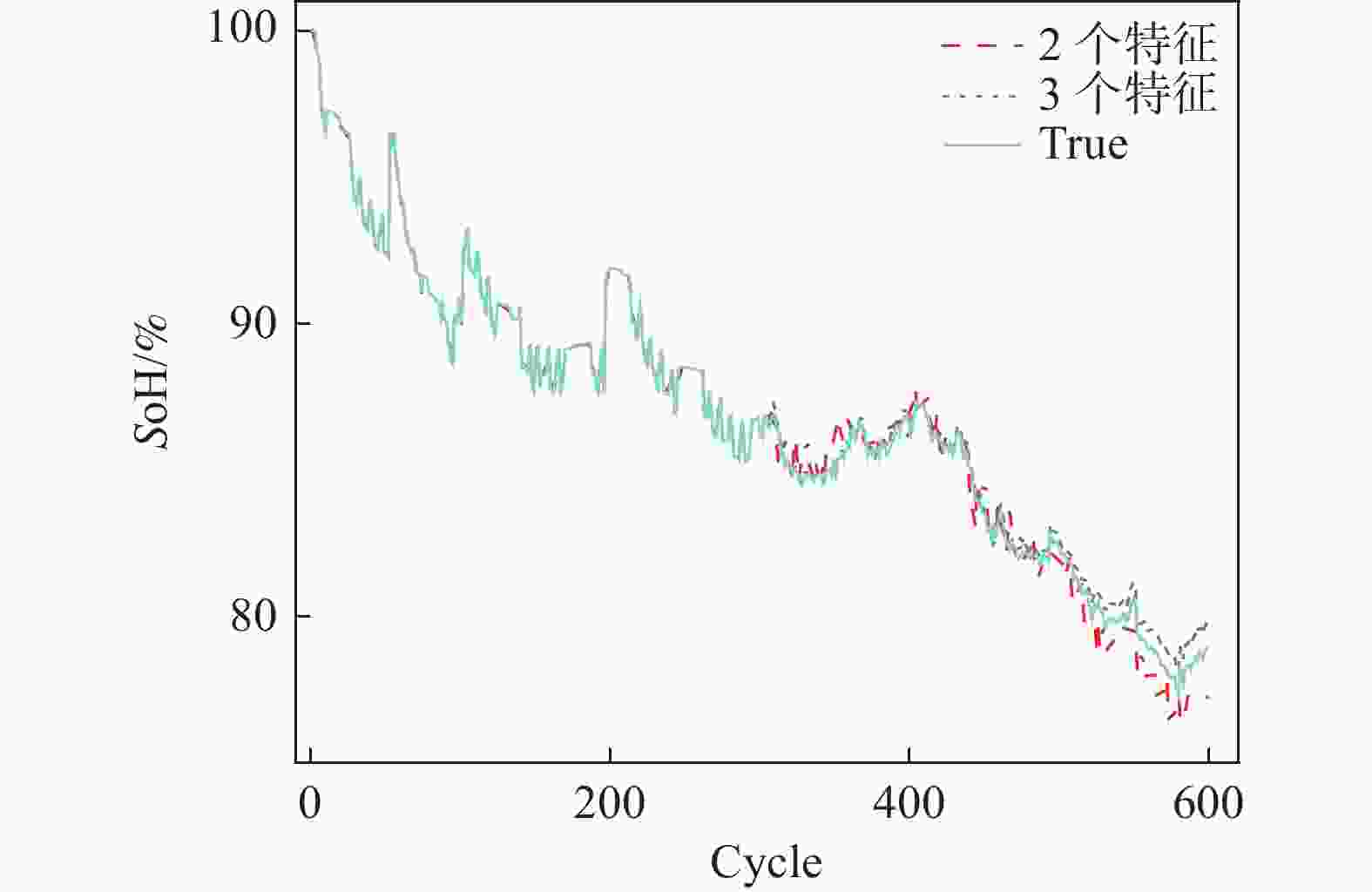
Figure 5. Comparison of results for different numbers of features
对于CS2-35电池,当使用2个特征(CCCT、ADV)进行SoH估计时,其RMSE为0.012 0。在相同模型参数的情况下,使用3个特征的RMSE为0.007 3。结果表明,使用3个特征时GRU神经网络对SoH的拟合效果更佳,故下文均以3个特征作为输入的情况进行讨论。
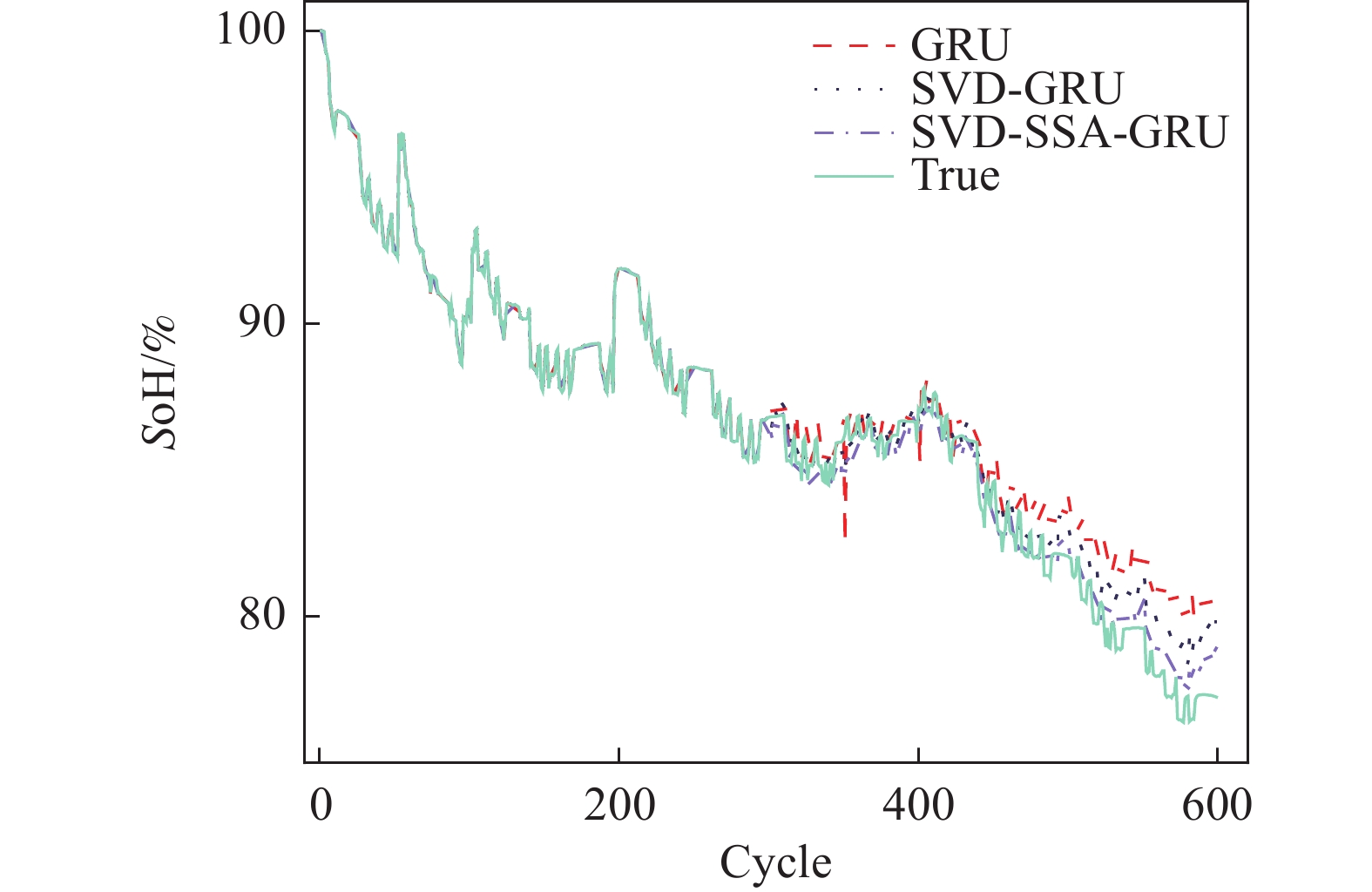
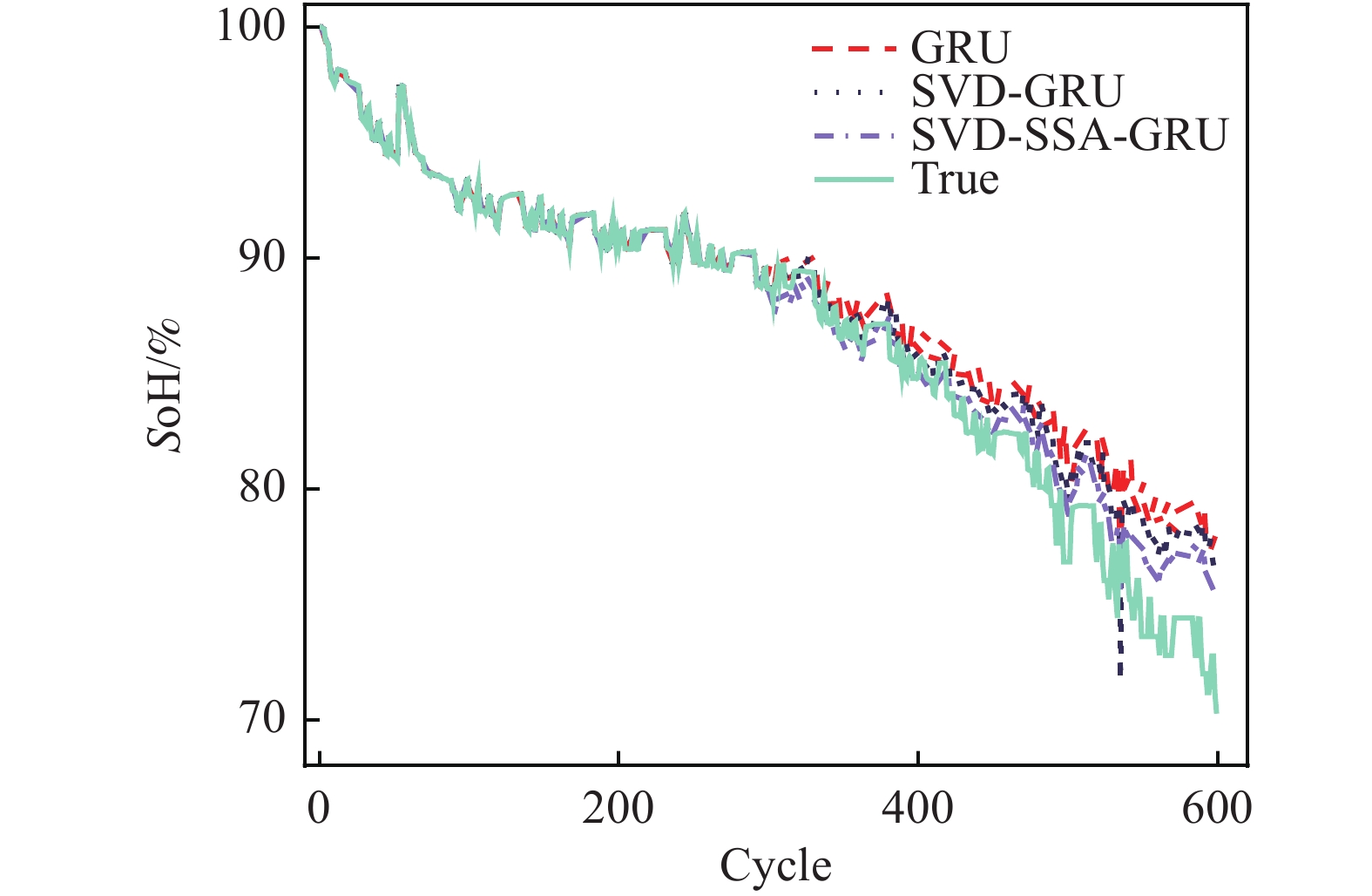
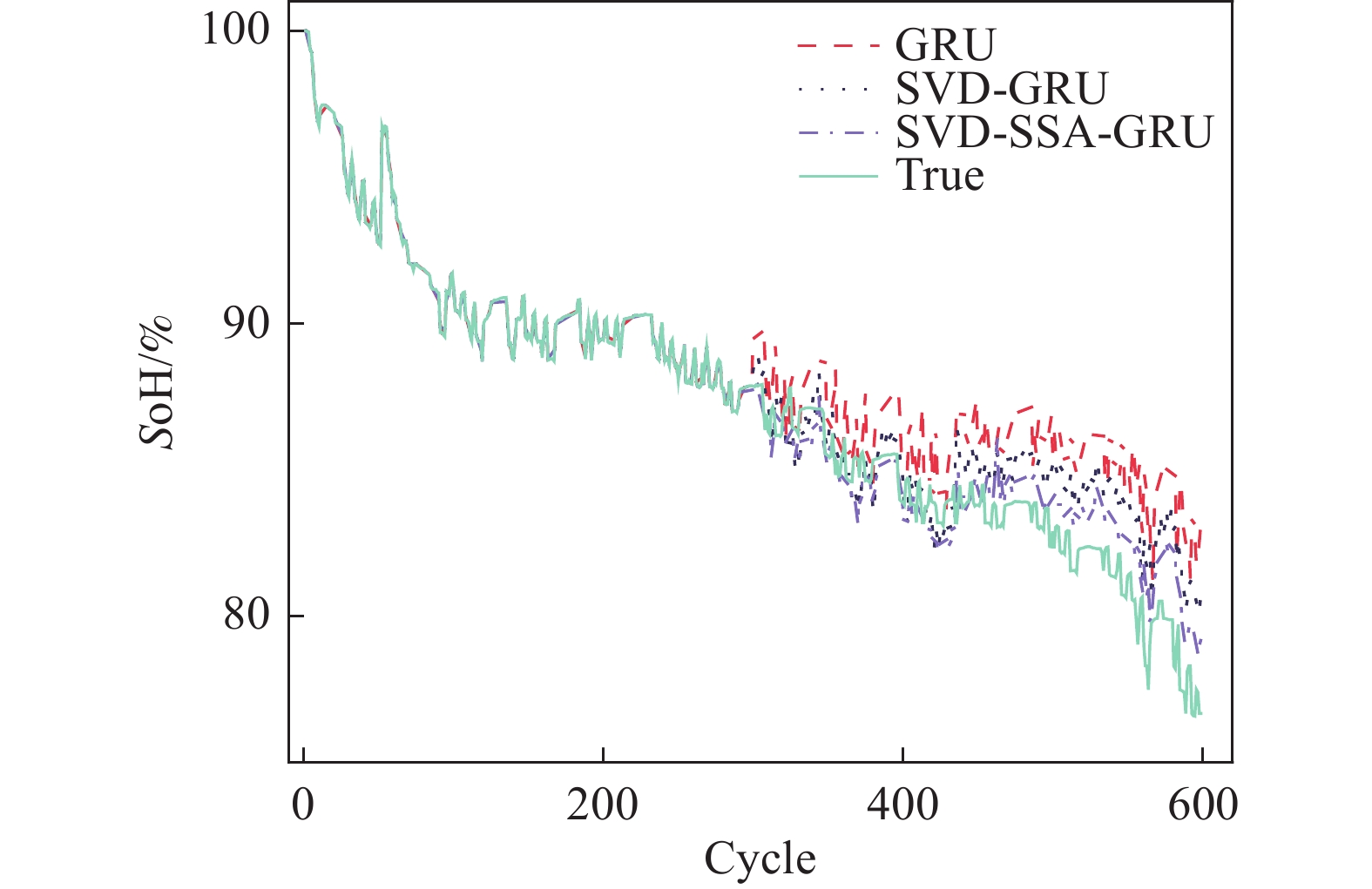
针对3组电池数据,3种模型对其SoH的估计效果如图6~图8所示。表4展示了经过麻雀算法优化后的GRU神经网络超参数值。为了更加准确地描述不同模型之间的精度,使用RMSE、MAE、MAPE进行评价,其值如表5所示。

Figure 6. CS2-35 health state estimation results
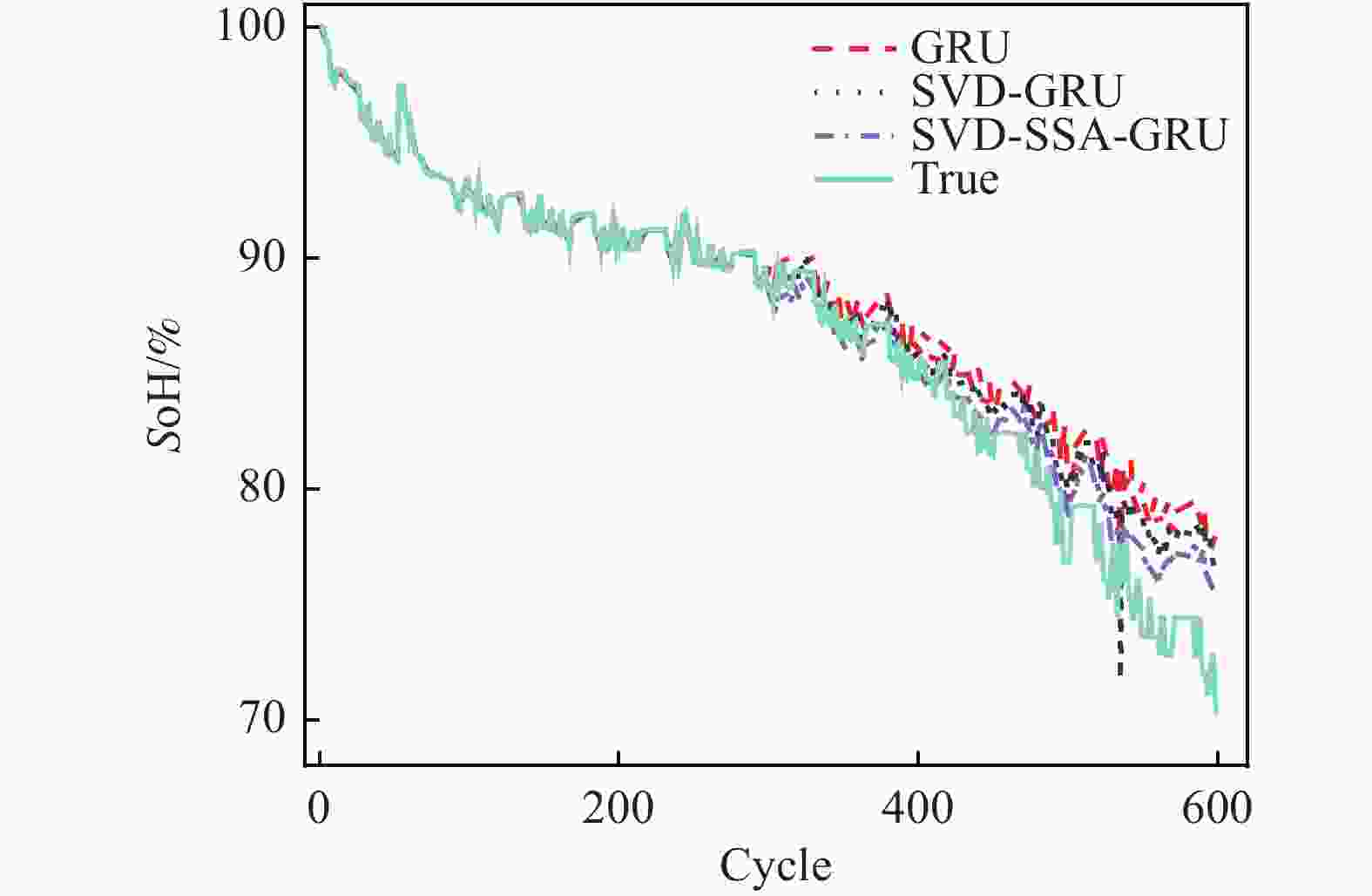
Figure 7. CS2-36 Health state estimation results
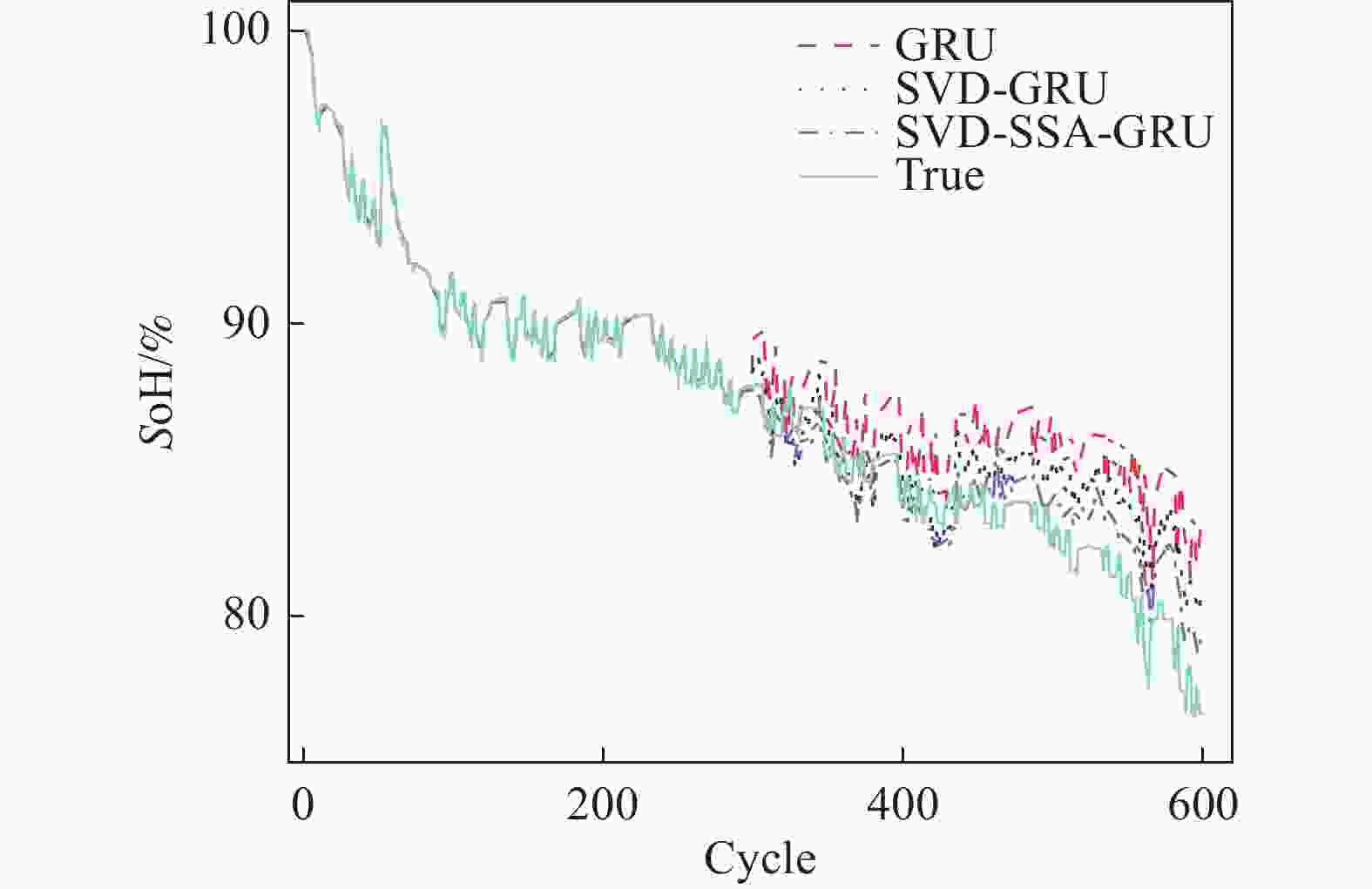
Figure 8. CS2-37 Health state estimation results
从图6~图8可以看出,SVD-SSA-GRU模型对锂离子电池SoH具有最好的估计效果,其估计曲线与真实数据曲线更加贴合,RMSE、MAE、MAPE均为3个模型中最小。同时,数据特征经过奇异值定阶降噪之后,其对于SoH的估计效果要优于原始数据。
具体到每个电池而言,其误差指标如表5所示。对于CS2-35电池,SVD-SSA-GRU模型的
RMSE、 MAE分别为7.3 × 10−3和5.9 × 10−3,比GRU模型降低了1.07 × 10−2、8 × 10−3,其对于SoH预测效果为3个电池中最佳。对于CS2-36电池,GRU、SVD-GRU、SVD-SSA-GRU模型的 RMSE分别为3.14 × 10−2、2.53 × 10−2和1.84 × 10−2,SVD-SSA-GRU比前者均有不同程度的减少。本研究所提模型对CS2-37电池的改善效果最为明显,SVD-SSA-GRU模型的RMSE为1.36 × 10−2,而GRU模型的RMSE为3.05 × 10−2,其RMSE在GRU模型的基础上减少了55.41%。总体上本研究所提模型对3个电池都能实现准确估计,其最大RMSE不超过1.84 × 10−2,同时SVD-SSA-GRU模型对SoH的估计精度对比SVD-GRU和GRU模型,均有不同程度的提升。 电池 学习率 迭代次数 GRU1神经元 GRU2神经元 C35 6.66 × 10−3 65 69 89 C36 9.04 × 10−3 53 74 89 C37 2.31 × 10−3 63 92 64 Table 4. Hyperparametric value
电池 GRU SVD-GRU SVD-SSA-GRU RMSE MAE MAPE RMSE MAE MAPE RMSE MAE MAPE CS35 0.018 0 0.013 9 1.73% 0.011 5 0.008 9 1.10% 0.007 3 0.005 9 0.72% CS36 0.031 4 0.025 0 3.21% 0.025 3 0.019 4 2.51% 0.018 4 0.013 7 1.76% CS37 0.030 5 0.026 1 3.18% 0.019 9 0.016 3 1.98% 0.013 6 0.010 8 1.32% Table 5. Comparison of SoH estimation results
-
本文提出一种基于奇异值定阶降噪和麻雀搜索算法优化GRU神经网络的电池SoH预测方法,使用先进生命周期工程中心的电池数据集验证所提方法的有效性。首先基于电池老化机理提出了3个特征指标分别为CCCT、CVCT、ADV,并计算了特征指标与SoH的Spearman相关系数。然后应用奇异值分解技术进行数据降噪,并使用麻雀搜索算法进行GRU神经网络模型的参数优化。最后基于公开数据集验证了所提模型的有效性,并对比分析了不同模型对于SoH的估计效果,验证了本方法的优越性。未来的研究将关注模型的鲁棒性,使用先进的深度学习算法,进一步提高SoH的预测精度。
Assessment Method for Health State of Li-Ion Batteries Based on Sparrow Search Algorithm
doi: 10.16516/j.gedi.issn2095-8676.2023.06.010
- Received Date: 2023-02-07
- Rev Recd Date: 2023-03-08
- Available Online: 2023-12-26
- Publish Date: 2023-11-10
-
Key words:
- lithium battery /
- state of health /
- data noise reduction /
- sparrow search algorithm /
- neural network
Abstract:
| Citation: | WANG Chao, CHEN Qi, GU Xinmei, JIANG Hu, GUO Fang, HUANG Guangshan, ZHU Shanshan. Assessment Method for Health State of Li-Ion Batteries Based on Sparrow Search Algorithm[J]. SOUTHERN ENERGY CONSTRUCTION, 2023, 10(6): 89-97. doi: 10.16516/j.gedi.issn2095-8676.2023.06.010

|

 DownLoad:
DownLoad: