
-
近年来,电量集抄已成为各大电网企业电量采集的重要方式。然而受通信不稳定等因素影响,电量集抄数据中可能存在异常数据问题。随着集抄技术的快速发展,如何自动高效的辨识异常数据,已成为集抄技术推广应用中面临的重要问题。
异常数据辨识的基本原理在于依据数据自身规律,定位数据序列中的异常数值。在电力系统生产运行的众多技术领域均需要解决异常数据辨识问题,然而由于数据自身规律差异,使得不同领域不同类型的异常数据辨识其方法并不一致[1,2,3,4]。能量管理系统(Energy Management System,简称EMS系统)中主要采用状态估计方法来分析各状态量的数据异常[1]。在负荷预测业务中,主要通过负荷数据与气温、节假日等数据的相关性分析,来对预测或量测结果校验,提出其中的不良数据[2,3,4]。在设备状态监测领域,则基于设备运行状态的特征分析,通过分析同类设备采集量之间的数据关系,来实现对设备状态监测量的异常辨识[5]。文献[6]介绍了用电类型数据自动辨识模拟机的原理和实践情况,用电数据异常辨识一方面需要从时间角度出发分析数据时序关系,另一方面需要分析负荷、气象等因素的相关性,通过综合分析得到辨识结果。文献[7,8,9]则从数据特征分析方法出发,将基于B样条小波分析方法、流式计算方法、数据挖掘方法等新的数据分析方法引入异常辨识,以提升数据辨识效率。
本文研究的重点是发电企业日发电量数据异常辨识问题。首先基于日发电量数据的自身特征,运用特征聚类的分析方法,研究不同类型电源的运行特征,提出不同类型电源不良数据的辨识条件;接着基于该判别条件构建了基于特征聚类分析的大规模发电数据异常辨识方法;最后以南方电网某省区的实际数据,介绍了本文所提出方法的有效性。
HTML
-
所谓特征聚类分析,是指在发电数据辨识过程中,从发电数据自身特性出发,根据不同类型电源的运行特征将具有同一类运行规律的电源汇总成一个类型,提出其特征判定条件的分析方法。
不同类型电源运行特征不同,根据其在时间尺度上的差别,发电数据辨识特征聚类分析可以分为纵向聚类和横向聚类两个方面。
纵向聚类分析,是指通过某一发电资源历史数据变化规律得到的聚类特征;横向聚类分析,是指通过同一类型发电资源在同一时间断面上的相互关系特征分析得到的聚类特征。不同类型电源具有不同的聚类特征,可能同时具有横向和纵向聚类特征,也可能仅有横向或纵向聚类特征。
-
本文所指的传统电源包括:大型火电、水电和核电。尽管上述电源在生产流程等并不一致,然而从厂用电率上上述电源具有纵向一致性,表现在:
1)不同电厂的厂用电率分布有所不同。
2)同一电厂不同开机方式下厂用电率分布不同。
3)同一电厂相同开机方式下厂用电率分布规律较为显著。
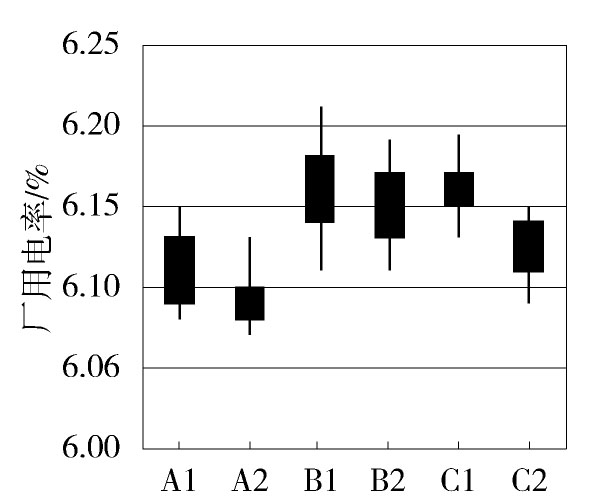
如图1所示,为用股价图表示的单机容量600 MW,机组数均为2台的三个火电厂在不同开机情况下的厂用电率分布。A1、A2、B1、B2、C1、C2分别表示火电厂A、B、C开机数量为1台或2台的情况。股价图的最高、最低、开盘、收盘四个指标分别代表该开机方式下电厂全年统计中最高厂用电率、最低厂用电率和以厂用电率全年统计足最大分布概率为中心上下各推40%概率情况的上下限。

Figure 1. Power utilization rate of thermal power
观察图1,不难发现由于装机不同、锅炉特性不同,开机方式不同,厂用电率将有所不同,但是在同一电厂相同开机方式下,其厂用电率分布较为集中,据统计其数据分布一般不超过0.2%[10],则上述偏差对于一个装机1.2 GW的火电厂,可近似折算电量40 MWh,占其发电量的0.2%。该数据误差在发电数据辨识中完全满足要求。
而大型水电、核电也具有相同的规律特征,这里不再赘述。据此可以统计每一个传统电源不同开机情况下的厂用电率分布,在通过人工分析可以认定数据准确的前提下,假设某电厂i日厂用电率最大、最小分别为
((1)) 式中:
((2)) 式中:
需要特别说明的是,由于大型水电机组在一日内存在多次启停,难以严格给出其开机数量情况,故可直接对其不同发电量下的厂用电率进行统计,其结果是一致的。
-
本文所指的新能源包括:风电、光伏、小水电为代表的电源类型。与传统电源相比,其发电量受自然条件影响很大,来风、降水、气温等都会对上述电源的发电量产生较大影响,导致其厂用电率指标也会发生较大波动,难以通过纵向聚类特性进行发电量数据辨识。而从横向来说,由于同一地区气候条件相似,则在同一地区的风电、光伏、小水电其电量往往呈现高度的相似性。
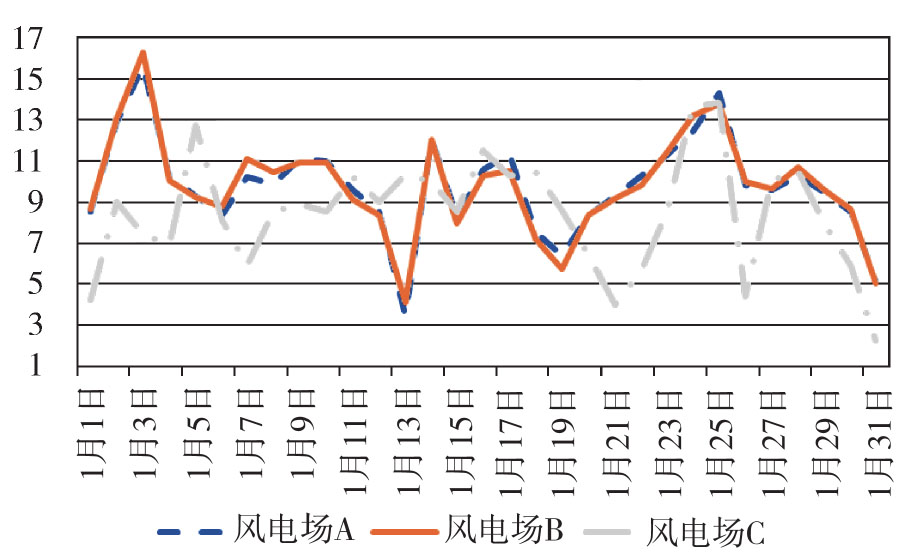
如图2所示,为位于某省的三个风电场某年1月份逐日利用小时数变化趋势图。可以发现虚线表示的风电场A和实线表示的风电场B逐日利用小时数非常接近,而尽管处于同一个省,点画线表示的风电场C逐日利用小时数与风电场A和风电场B相差较大。其原因在于风电场A和风电场B空间位置比较接近,处于同一“风带”,而风电场C则相距较远。

Figure 2. Wind plant utilization time
如果将各风电场逐日利用小时数作为数据系列,则风电场A与风电场B的相关系数为0.87,而风电场A与风电场C的相关系数仅有0.35。
同一地区的光伏、同一流域的小水电均满足该特性。据此可通过对历史数据分析,得到各风电场、光伏电站、小水电站出力的相关系数,人工给定其相关系数一致性门槛值,若待辨识日的风电场、光伏电站、小水电不满足该相关系数门槛值要求,则认为该数据有误,判别公式可表示为:
((3)) 式中:
1.1 特征聚类分析
1.2 传统电源的纵向聚类特性


1.3 新能源的横向聚类特性

-
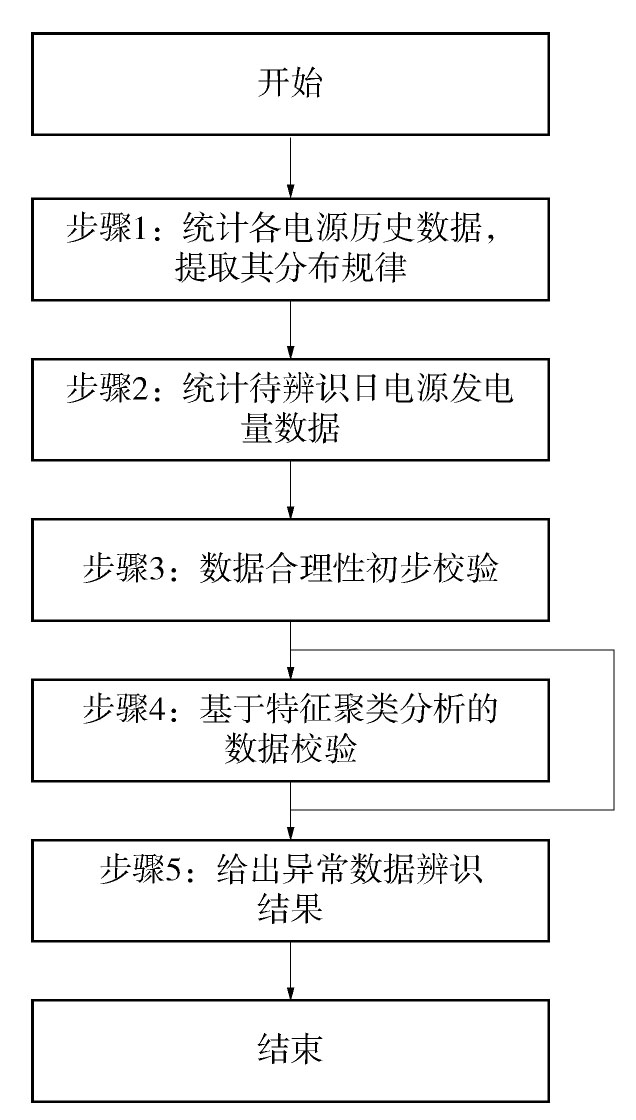
基于上述分析,本文所提出的基于特征聚类分析的大规模发电数据异常辨识方法流程如图3所示。其主要流程包括如下五个步骤:

Figure 3. Implementation flow chart
1)统计各电源历史数据,提取其分布规律。
2)统计待辨识日电源发电量数据。
3)数据合理性初步校验。
4)基于特征聚类分析的数据校验。
5)给出异常数据辨识结果。
-
题对大型火电、水电、核电等传统电源,获取历史逐日发电量、上网电量数据。要求该数据均通过人工检验,确保数据质量。设某传统电源i第j日的发电量和上网电量分别为
对于风电、光伏、小水电等新能源,获取其历史逐日发电量。同样对数据质量要求满足人工校验的基本要求。设某新能源i第j日的发电量为
-
从计量自动化系统中抽取待辨识日每个电站的运行数据,不同类型电站抽取数据不同,如表1所示。
类型 抽取数据 火电 开机台数、单机容量、发电量、上网电量 水电 装机容量、发电量、上网电量 核电 开机台数、单机容量、发电量、上网电量 风电 装机容量、发电量 光伏 装机容量、发电量 小水电 装机容量、发电量 Table 1.
Extracted data -
初步校验的目的在于对上述数据的合理性做直观判断,其主要方式是计算各电源的利用小时数,判断明显不合理的异常数据。
各电源的利用小时数可由其发电量和装机容量计算得到。当利用小时数为负值或超过24 h,则上述数据明显异常。
若初步校验即发现发电量数据存在异常,则直接将上述异常结果输出,执行步骤5;否则转入基于特征聚类分析的数据校验,执行步骤4。
-
对传统电源待预测日的厂用电率可由其发电量和上网电量,参考公式(2)计算得到。对照该开机或发电量下的厂用电率变化范围上下限,若该日厂用电率超过该范围限值,则说明该日数据异常。
对新能源电站,将相关电站群的待辨识日发电量数据汇入其发电量数据序列,计算其扩展待辨识日发电量数据后的新序列间相关系数。若相关电站群中存在某电站待辨识日内发电量扩展后导致扩展序列与其他电站扩展序列相关系数低于给定门槛值,则说明该电站发电量数据为异常数据。
2.1 实施流程
2.2 历史数据分析
2.3 获取待辨识日数据
2.4 初步校验
2.5 特征聚类分析
-
以南方电网某省实际数据为基础构造算例验证本文所提出方法的有效性。这里将选取1个发电厂和1个包含3个风电场的相关电源群作为对象进行分析。上述电源的基本信息如表2所示。
名称 单机容量/MW 总装机/MW 火电厂A 600 1 200.0 风电场A — 320.0 风电场B — 112.5 风电场C — 65.5 Table 2.
Generation plants basic data -
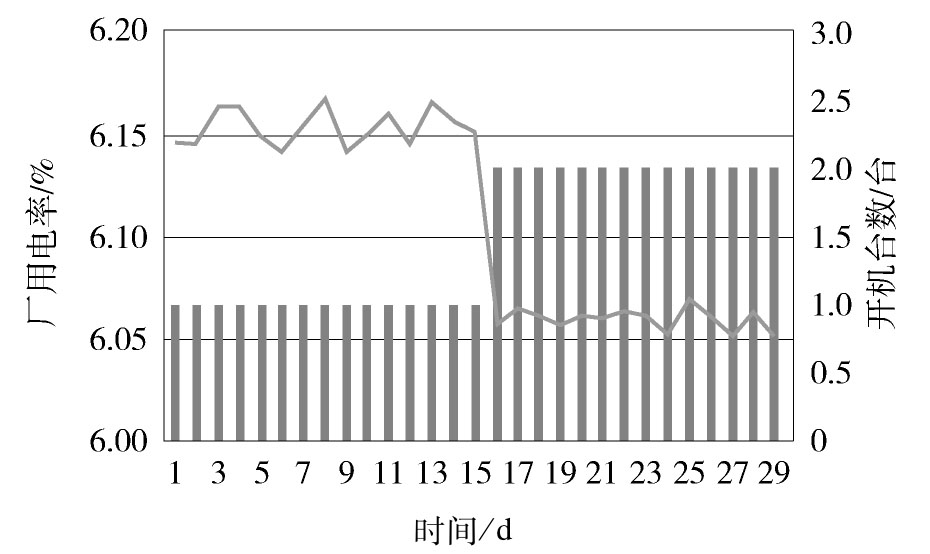
对火电厂A,选取了经核准的历史30 d发电量、上网电量数据,如图4所示,为其厂用电率和开机数变化趋势图。

Figure 4. History data of power plant A
在开机数为1台时,其厂用电率变化范围为[6.14%,6.17%]。在开机数为2台时,其厂用电率变化范围为[6.05%,6.07%]。据此,规定该电厂厂用电率辨识范围,开机台数为1台时,厂用电率须处于[6.13%,6.18%],开机台数为2台时,厂用电率须处于[6.04%,6.08%]。上述门槛值适度放大主要是考虑所选取历史数据量较少。
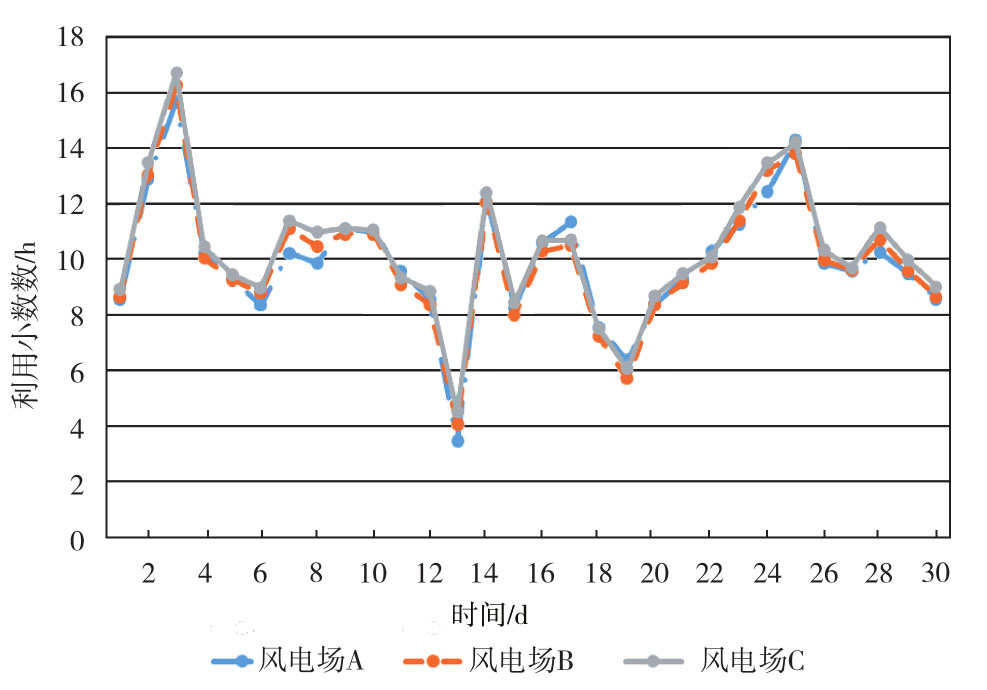
对三个风电场,其利用小时趋势图如图5所示。三个风电场之间相关系数为:γ(A,B)=0.95,γ(A,C)=0.94,γ(B,C)=0.91。设定相关性系数门槛为0.90。

Figure 5. Wind plant utilization time
-
待预测日基础数据如下表3所示。火电厂A的厂用电率为0.48%,明显超出厂用电率门槛范围,该数据存在异常。而经过校验,在将待辨识日风电场数据补充进历史数据序列后,γ(
名称 开机数/台 发电量/MWh 上网电量/GWh 火电厂A 2 18 968 18.876 风电场A — 120.4 — 风电场B — 32.8 — 风电场C — 25.7 — Table 3.
Data of identification day
3.1 基础数据
3.2 历史数据分析
3.3 待预测日辨识
-
针对大规模发电量集抄后的异常数据辨识问题,本文结合电力系统发电数据异常辨识的客观需要,分析了传统电源的纵向聚类特征和新能源的横向聚类特征,提出了适应不同电源的异常判据。基于该特征聚类分析的发电数据异常辨识方法在南方电网得到了广泛应用,大幅提升数据质量。

 DownLoad:
DownLoad: